一、外键
1. 概念
一个表的主键A在另外一个表B中出现,则A是表B的外键
2. 作用
- 本身也是约束,为了防止无效信息插入
- 但会降低表的更新效率,一般很少使用
3. 语法
-- 外键的使用
-- 向goods表里插入任意一条数据
insert into goods (name,cate_id,brand_id,price) values('老王牌拖拉机', 10, 10,'6666');
-- 创建外键第一种方式:通过alter table
-- 约束 数据的插入 使用 外键 foreign key
-- alter table goods add foreign key (brand_id) references goods_brands(id);
alter table goods add foreign key(cate_id) references goods_cates(id);
alter table goods add foreign key(brand_id) references goods_brands(id);
-- 创建外键第二种方式:create table 时创建
create table teacher(
id int not null primary key auto_increment,
name varchar(10),
s_id int not null,
foreign key(s_id) references school(id)
);
-- 失败原因 老王牌拖拉机 delete
-- delete from goods where name="老王牌拖拉机";
delete from goods where name="老王牌拖拉机";
-- 如何取消外键约束
-- 需要先获取外键约束名称,该名称系统会自动生成,可以通过查看表创建语句来获取名称
show create table goods;
-- 获取名称之后就可以根据名称来删除外键约束
alter table goods drop foreign key goods_ibfk_1;
alter table goods drop foreign key goods_ibfk_2;
二、视图
1. 概念

2. 语法
-- 1.创建视图 create view 视图名称 as select语句;
create view v_students as
select s.id,s.name,s.age,s.gender,c.name as cls_name
from students as s
inner join classes as c
on s.cls_id=c.id;
-- 2.查看视图 show tables
show tables;
-- 3.查询视图 select * from 视图名称
select * from v_students;
-- 4.删除视图 drop view 视图名称
drop view v_students;
三、事务
1. 概念
事务就是用户定义的一系列执行SQL语句的操作, 这些操作要么完全地执行,要么完全地都不执行,它是一个不可分割的工作执行单元。
2. 使用场景:
在日常生活中,有时我们需要进行银行转账,这个银行转账操作背后就是需要执行多个SQL语句,假如这些SQL执行到一半突然停电了,那么就会导致这个功能只完成了一半,这种情况是不允许出现,要想解决这个问题就需要通过事务来完成。
3. 四大特性
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
-
原子性: 一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性
-
一致性: 数据库总是从一个一致性的状态转换到另一个一致性的状态。(在前面的例子中,一致性确保了,即使在转账过程中系统崩溃,支票账户中也不会损失200美元,因为事务最终没有提交,所以事务中所做的修改也不会保存到数据库中。)
-
隔离性: 通常来说,一个事务所做的修改操作在提交事务之前,对于其他事务来说是不可见的。(在前面的例子中,当执行完第三条语句、第四条语句还未开始时,此时有另外的一个账户汇总程序开始运行,则其看到支票帐户的余额并没有被减去200美元。)
-
持久性: 一旦事务提交,则其所做的修改会永久保存到数据库。 说明: 事务能够保证数据的完整性和一致性,让用户的操作更加安全。
4. 事务管理
-- 事务开启
start transaction;
-- 结束事务
commit;
-- 回滚
rollback; -- 在commit之前 如果想退回start之前的状态可以使用roolback
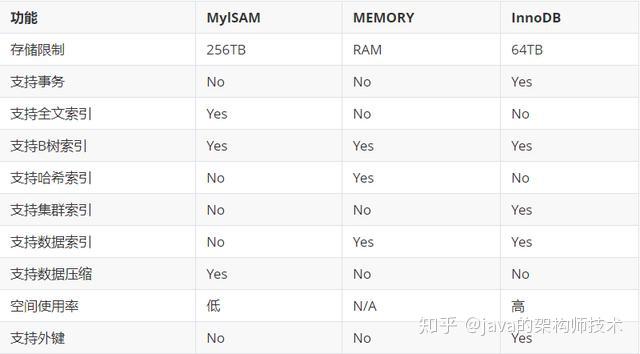
四、引擎对比
五、索引
1. 概念
索引在MySQL中也叫做“键”,它是一个特殊的文件,它保存着数据表里所有记录的位置信息,更通俗的来说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
2. 使用场景
当数据库中数据量很大时,查找数据会变得很慢,我们就可以通过索引来提高数据库的查询效率。
3. 索引的使用

-- 查看索引
show index from 表名;
-- 创建索引的语法格式
-- alter table 表名 add index 索引名[可选](列名, ..)
-- 给name字段添加索引
alter table classes add index my_name (name);
-- 删除索引的语法格式
-- alter table 表名 drop index 索引名
-- 如果不知道索引名,可以查看创表sql语句
show create table classes;
alter table classes drop index my_name;
4. 验证索引性能
-- 开启运行时间监测:
set profiling=1;
-- 查找第1万条数据ha-99999
select * from test_index where title='ha-99999';
-- 查看执行的时间:
show profiles;
-- 给title字段创建索引:
alter table test_index add index (title);
-- 再次执行查询语句
select * from test_index where title='ha-99999';
-- 再次查看执行的时间
show profiles;
六、数据库设计三范式
1. 概念
范式: 对设计数据库提出的一些规范,目前有迹可寻的共有8种范式,一般遵守3范式即可。
2. 数据冗余
指的是数据之间的重复,可以说是同一数据存储在不同数据文件中的现象;
3. 范式划分
- 第一范式(1NF): 强调的是列的原子性,即列不能够再分成其他几列。
- 第二范式(2NF):满足1NF,另外包含两部分内容,一是表必须有一个主键;二是非主键字段 必须完全依赖于主键,而不能只依赖于主键的一部分。
- 第三范式(3NF):满足2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。
七、ER模型

八、python连接数据库
1. 安装pymysql
sudo pip3 install pymysql
2. 使用pymsql查询操作
# 导入 pymysql 包
import pymysql
# 调用pymysql模块中的connect()函数来创建连接对象
conn = pymysql.connect(host='localhost', port=3306, user='root', password='mysql',database='python', charset='utf8')
# 获取游标对象
cursor = conn.cursor()
# 查询 SQL 语句
sql = "select * from students;"
# 执行 SQL 语句 返回值就是 SQL 语句在执行过程中影响的行数
row_count = cursor.execute(sql)
print("SQL 语句执行影响的行数%d" % row_count)
# 取出结果集中一行数据, 例如:(1, '张三')
# print(cursor.fetchone())
# 取出结果集中的所有数据, 例如:((1, '张三'), (2, '李四'), (3, '王五'))
for line in cursor.fetchall():
print(line)
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
3. 使用pymysql增删改操作
import pymysql
# 创建连接对象
conn = pymysql.connect(host='localhost', port=3306, user='root', password='mysql',database='python', charset='utf8')
# 获取游标对象
cursor = conn.cursor()
try:
# 添加 SQL 语句
# sql = "insert into students(name) values('刘璐'), ('王美丽');"
# 删除 SQ L语句
# sql = "delete from students where id = 5;"
# 修改 SQL 语句
sql = "update students set name = '王铁蛋' where id = 6;"
# 执行 SQL 语句
row_count = cursor.execute(sql)
print("SQL 语句执行影响的行数%d" % row_count)
# 提交数据到数据库
conn.commit()
except Exception as e:
# 回滚数据, 即撤销刚刚的SQL语句操作
conn.rollback()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
九、SQL语句参数化与SQL注入
1. 什么是SQL注入?
用户提交带有恶意的数据与SQL语句进行字符串方式的拼接,从而影响了SQL语句的语义,最终产生数据泄露的现象。
2. 如何防止SQL注入?
SQL语句参数化:SQL语言中的参数使用%s来占位,此处不是python中的字符串格式化操作 将SQL语句中%s占位所需要的参数存在一个列表中,把参数列表传递给execute方法中第二个参数
from pymysql import connect
def main():
find_name = input("请输入物品名称:")
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='mysql',database='jing_dong',charset='utf8')
# 获得Cursor对象
cs1 = conn.cursor()
# 非安全的方式
# 输入 ' or 1 = 1 or ' (单引号也要输入)
# sql = "select * from goods where name='%s'" % find_name
# print("""sql===>%s<====""" % sql)
# # 执行select语句,并返回受影响的行数:查询所有数据
# count = cs1.execute(sql)
# 安全的方式
# 构造参数列表
params = [find_name]
# 执行select语句,并返回受影响的行数:查询所有数据
count = cs1.execute("select * from goods where name=%s", params)
# 注意:
# 如果要是有多个参数,需要进行参数化
# 那么params = [数值1, 数值2....],此时sql语句中有多个%s即可
# %s 不需要带引号
# 打印受影响的行数
print(count)
# 获取查询的结果
# result = cs1.fetchone()
result = cs1.fetchall()
# 打印查询的结果
print(result)
# 关闭Cursor对象
cs1.close()
# 关闭Connection对象
conn.close()
if __name__ == '__main__':
main()